Research Blog
Interactive Task Guidance as a Testbed for Multimodal Intelligence
From turn-based multimodal chat to real-world, always-on assistance.

State-of-the-art multimodal LLMs are impressive but most of them still operate in a fundamentally turn-based way: they respond only when prompted. That works well for many text- and image-based tasks, but it is not how intelligence works in the real world. From birds to dogs, animals interact with their environments continuously, integrating multimodal sensory inputs and selecting actions in real time. Replicating this kind of continuous perception and action in AI would be an important step toward AGI and general-purpose robotics, since real-world intelligence requires intelligent agents to perceive, reason, and act over continuous streams of multimodal input.
From turn-based chat to always-on multimodal assistance
This shift is already visible in frontier systems. Google’s Gemini Live adds real-time spoken interaction together with camera and screen sharing,[1] while Project Astra explores a broader “universal assistant” vision with multimodal memory, tool use, action-taking, and proactive responses.[2]
But today’s frontier models are still largely limited to user-initiated conversations: you “Go Live,” speak, and get spoken responses.[1] That is still different from a truly always-on assistant that decides for itself when to intervene.
Gemini Live / Project Astra style interaction
Gemini Live demonstrates fluent, voice-first multimodal interaction grounded in live visual context.[3]
Streaming benchmarks are advancing fast
Academic work has been moving quickly as well. Two especially useful trackers are Awesome Streaming Video Understanding[4] and Awesome Streaming LLMs[5], which curate models, methods, datasets, and taxonomies for this rapidly growing area.
At the benchmark level, three influential recent efforts are StreamingBench[6], OVO-Bench[7], and RIVER[8] (among others). Together, these benchmarks move beyond offline video QA toward temporally grounded, streaming interaction.
What these benchmarks actually test
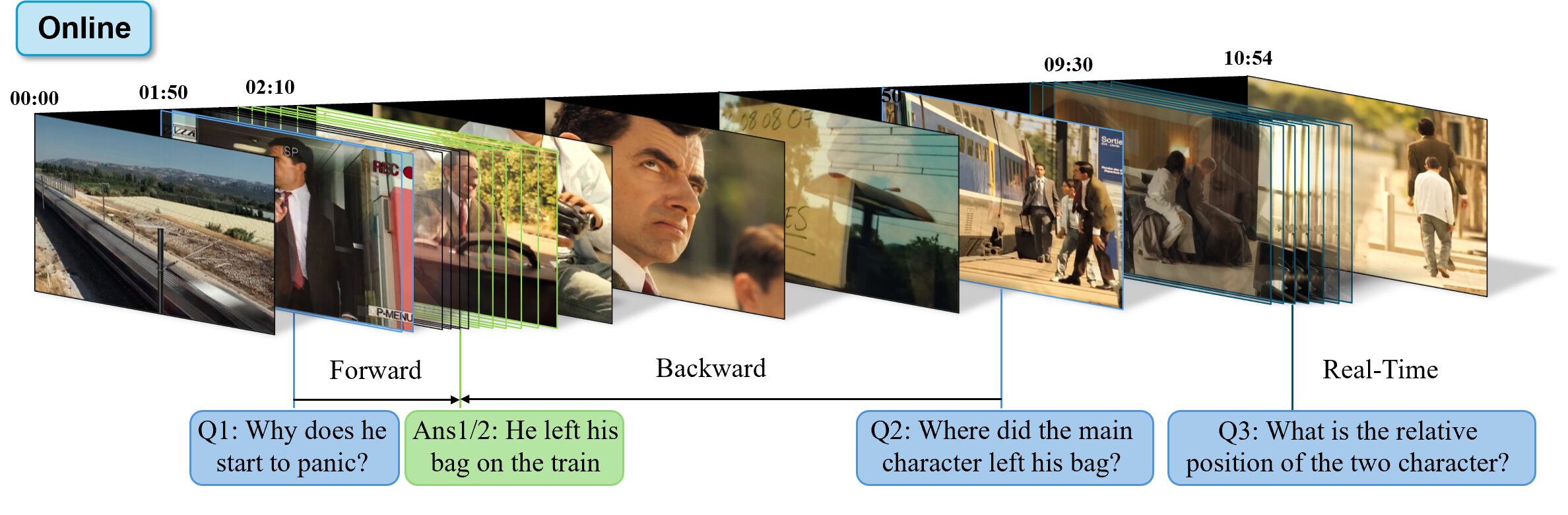
Tasks in these benchmarks can be broadly divided into:
Understanding current events: tests the ability to interpret what is happening right now from the current stream. In OVO-Bench, this appears as "Real-Time Visual Perception", which covers objects, actions, attributes, OCR, spatial relationships, and immediate online-style questions.[7]
Recalling past events: tests the ability to recover information that is no longer visible. OVO-Bench’s “Backward Tracing” makes this concrete with examples like “Who did I communicate to when chopping eggplants?”, “What did I drop in the bowl in the sink?”, and “What food did I chop?”[7]
Tracking future events: tests the ability to keep monitoring until a relevant event actually happens. In OVO-Bench, “Forward Active Responding” includes tasks like Repetition Event Count and Sequential Steps Recognition, where the correct behavior is continued observation followed by a response at the right moment.[7]
Knowing “when to say”: tests the ability to decide whether to answer now or wait for more evidence. OVO-Bench’s “Clues Reveal Responding” captures this especially well: the model should stay silent until enough visual evidence has accumulated to support a correct response.[7]
But real-world intelligence is harder than benchmark skills in isolation
These benchmark capabilities are important, but they are evaluated in relative isolation. Real-world tasks usually require several of them at once: understanding the present, remembering past progress, anticipating what comes next, detecting when something has gone wrong.
Recent work reinforces how much room there still is to improve evaluation. In particular, SimpleStream very recently showed that an off-the-shelf VLM using only a tiny sliding window of recent frames can already match or beat many specialized streaming models.[9] That suggests current benchmarks are useful, but still not yet sufficient stress tests for real-world multimodal intelligence.
Interactive task guidance: a stronger and more realistic testbed
A particularly compelling next step is interactive task guidance: benchmarks where an AI system must guide a person through a real-world task such as a fitness routine or a recipe, providing instructions, checking progress, and intervening when mistakes occur.[10][11]
This setup naturally combines perception, memory, anticipation, temporal grounding, and proactive communication in one unified problem. It is much closer to the challenges of the real world.
This is the motivation behind the Qualcomm Exercise Videos Benchmark and Dataset (NeurIPS 2024), which introduced fitness coaching as a benchmark for situated interaction. The key challenge is not just understanding human motion, but recognizing mistakes and delivering the right feedback at the right time, as the activity unfolds.[10]
This theme continues in Qualcomm Interactive Cooking Benchmark and Dataset (NeurIPS 2025). This benchmark requires models to guide a person through a recipe: providing the next instruction, detecting successful completion, identifying mistakes, and issuing corrective feedback at the right moment.[11]
Why this matters
Guiding a person through a real-world task is one of the cleanest testbeds we have for benchmarking multimodal intelligence with continuous sensory inputs.[10][11] Such benchmarks would not only enable future interactive assistants running on personal devices such as phones and smart glasses but also test capabilities we eventually want in embodied agents and household robots. It is also particularly appealing as a testbed for multimodal embodied intelligence because it conveniently disentangles thinking from acting: the model provides the intelligence and guidance, while the human is the action expert executing the task.
References
- Google. Gemini Live — get real-time voice assistance from Gemini. Product page, 2026. Link
- Google DeepMind. Project Astra. Research prototype overview, 2026. Link
- CNET. Google demos “Gemini Live” AI Android voice chatbot. YouTube video, August 13, 2024. Link
- Yang011013. Awesome Streaming Video Understanding. GitHub repository. Link
- EIT-NLP. Awesome Streaming LLMs. GitHub repository, 2026. Link
- Lin, J., Fang, Z., Chen, C., Wan, Z., Luo, F., Li, P., Liu, Y., and Sun, M. StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding. arXiv preprint arXiv:2411.03628, 2024. Link
- Li, Y., Niu, J., Miao, Z., Ge, C., Zhou, Y., He, Q., Dong, X., Duan, H., Ding, S., Qian, R., Zhang, P., Zang, Y., Cao, Y., He, C., and Wang, J. OVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding? CVPR, 2025. Link
- Shi, Y., Zhao, Q., Jiang, T., Zeng, X., Wang, Y., and Wang, L. RIVER: A Real-Time Interaction Benchmark for Video LLMs. arXiv preprint arXiv:2603.03985, 2026. Link
- Shen, Y., Tian, S., Yang, J., and Liu, Z. A Simple Baseline for Streaming Video Understanding. arXiv preprint arXiv:2604.02317, 2026. Link
- Panchal, S., Bhattacharyya, A., Berger, G., Mercier, A., Böhm, C., Dietrichkeit, F., Pourreza, R., Li, X., Madan, P., Lee, M., Todorovich, M., Bax, I., and Memisevic, R. What to Say and When to Say it: Live Fitness Coaching as a Testbed for Situated Interaction. NeurIPS Datasets and Benchmarks Track, 2024. Link
- Bhattacharyya, A., Xu, B., Haresh, S., Pourreza, R., Liu, L., Panchal, S., Sigal, L., and Memisevic, R. Can Multi-Modal LLMs Provide Live Step-by-Step Task Guidance? NeurIPS, 2025. Link